Article by Dr. Mark Miesch, JEDI core team
JCSDA's Joint Effort for Data assimilation Integration (JEDI) is an innovative, next-generation data assimilation system that leverages modern software development practices to optimize both performance and extensibility. As the software approaches its initial public release, the JEDI user community continues to grow in size and diversity. Potential use cases for JEDI range from operational weather forecasts to computationally intensive research projects to graduate students learning data assimilation with the help of idealized "toy models" that can be run on a laptop. Even within a particular use case, development workflows often involve low-resolution testing on laptops and workstations before deploying to high performance computing (HPC) systems for production applications. Furthermore, high-end users without access to HPC systems are increasingly turning to commercial cloud providers such as Amazon Web Services (AWS), Microsoft Azure, and Google Cloud to acquire application-level computing resources on demand.
All this diversity means that users will want to run JEDI on a range of computing platforms, from state-of-the-art HPC systems (on-premise Supercomputers) to cloud instances, to small linux clusters to laptops. But this is a considerable technical challenge. Like other sophisticated modern software projects, JEDI leverages a number of open-source software packages, including UCAR/UCP/Unidata's Network Common Data Form (NetCDF), linear algebra libraries (LAPACK, Eigen), and versatile build systems (CMake, ecbuild). We make our build system, called the JEDI-stack (Figure 1, below), publicly available to help JEDI users install this list of dependencies on-premise, but many may not have sufficient time or personnel available to maintain this.
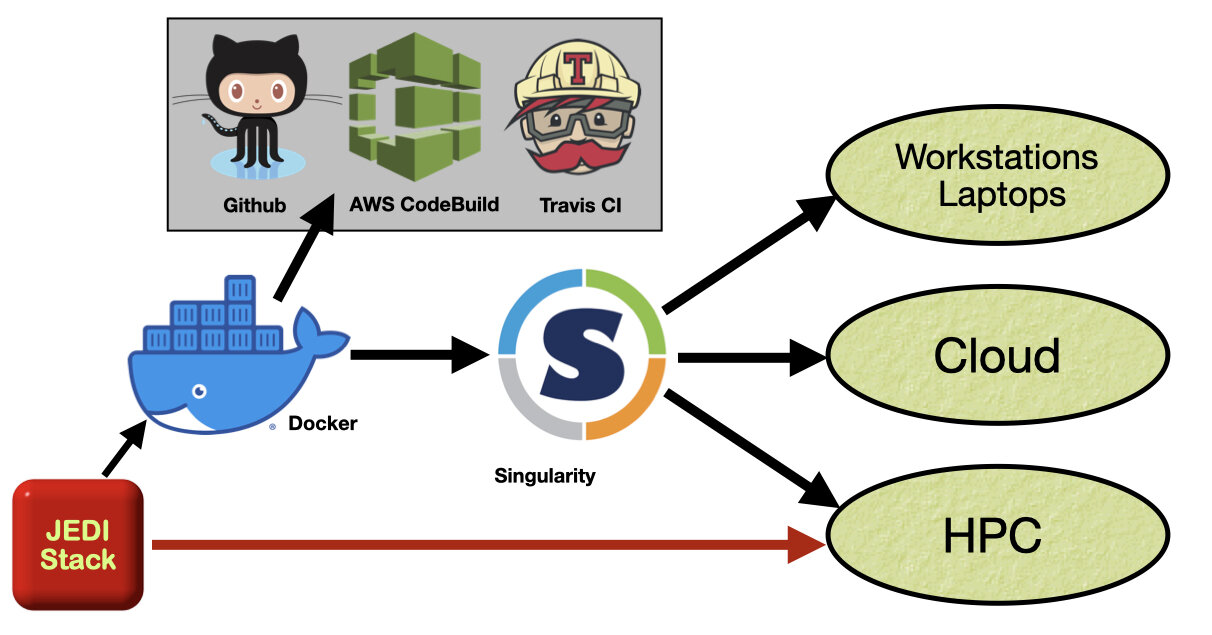
Figure 1. JEDI container workflow and JEDI-stack build system.
Containers to the rescue! Though the idea of software containers has been around for decades, their use has blossomed in recent years with the arrival of container providers such as Docker (2013) and Singularity (2016). For our purposes here, you can think of a software container as just a file (technically an image) that contains everything that is needed to run an application. Figure 1 highlights how we build and deploy containers for JEDI.
Docker and Singularity are commercial applications that provide the tools needed to build, deploy, and run software containers. So, for example, to run JEDI on her laptop, a user could first install Docker (free of charge). Then she could download the appropriate JEDI container image from a public web site (Docker Hub) and launch the container by running the Docker application. Then, she could immediately run a JEDI application without having to worry about building the code or its dependencies. The compiled code is already there in the container and ready to go. A process that could have taken days (installing dependencies, building JEDI and running your first application) is now reduced to minutes.
Containers can include the input data required to run sample applications, such as atmospheric and oceanic observations and background states from different numerical model forecasts. Equally important, they can exclude proprietary components such as the Intel compiler suite. This allows for the public distribution of Intel application containers without violating licensing agreements. Public releases of the JEDI software will be accompanied by containers that are ready to run with the source code and compiled applications from that release.
Containers offer reproducibility as well as portability. Users who use the same containers to run the same applications should always get the same results. Why are there multiple container providers? Docker is the industry standard and is widely available across different platforms, including Mac, Windows, and Linux laptops as well as cloud services. But, Docker was not designed to support scientific workflows on Supercomputers. Singularity ‘supercontainers’ provide a more familiar and optimized environment for scientific multi-node applications on HPC platforms.
The JEDI team has recently developed innovative Singularity containers for use on Supercomputers. These are among the first software containers in the atmospheric science community to demonstrate native performance across more than 800 compute cores (24-44 nodes) on three distinct HPC systems, namely the Discover system at the NASA Center for Climate Simulation (NCCS), the S4 (Satellite Simulations and Data Assimilation Studies) system at the University of Wisconsin-Madison’s Space Science and Engineering Center, and a high-performance parallel cluster (24 c5n.18xlarge nodes with EFA interconnect) on the Amazon cloud (AWS).
Native performance means that the application tested took approximately the same amount of time inside the container as it did when the JEDI code and its dependencies were compiled directly on the system, without the use of a container. This is demonstrated in Figure 2 below. Each bar in the Figure represents an average over 10 realizations of a parallel JEDI application, namely 3D Variational Data Assimilation of approximately 12 million observations using an FV3 model background. In making these comparisons, the same system (JEDI-stack) was used to build software dependencies both inside and outside the container (cf. Fig 1).

Figure 2. Performance of JEDI supercontainers on selected HPC systems.
For Discover and AWS, the performance inside and outside the container was found to be essentially the same, within the standard deviation of the timings (indicated by the black lines in Fig. 2). In other words, using the container incurs no overhead. On the primary S4 partition, the container overhead was about 7%. However, the best performance on S4 was achieved inside the container using 44 intel ivy-bridge nodes (S4-Ivy).
In short, this demonstrates that JEDI users can achieve the advantages of a container (portability, reproducibility) without sacrificing performance. And, this holds even for computationally intensive data assimilation applications that require HPC resources. Furthermore, the same Singularity containers can be run on traditional HPC systems, cloud platforms, workstations, and laptops (cf. Fig. 1). Optimizing containers efficiency on new HPC systems may still take some work, but this is minimal compared to the effort to maintain a full software stack.
As illustrated in Figure 1, the JEDI Singularity containers are built from the same pool of Docker containers that are used for Continuous Integration (CI; indicated by the grey box). CI is an established practice from the software development community whereby code changes are automatically tested before they are implemented. In the case of JEDI, the code base is stored on the GitHub web platform and any proposed changes to the main GitHub code base trigger automated testing through several cloud services, namely AWS CodeBuild and Travis CI. These tests ensure that the code runs successfully across different software environments (compilers and MPI libraries). No change is implemented until it passes all tests.
So, when you run JEDI in a container, you can be confident that you are running code that is reliable and efficient. And, armed with your JEDI container, there is virtually no limit to the places you can go.